# Получение данных
Основой работы получения данных из таблиц Савви является специальный динамический генератор запросов (Dynamic SQL Generator - DSG). Это механизм, позволяющий конвертировать запросы клиентов в SQL-запросы к таблице, таким образом получая возможность работать с неограниченными по длине таблицами не перегружая контекст модели и получая максимально точные ответы.
## Что позволяет?
Использование таблиц обычно необходимо для получения:
* актуальных цен на товары или услуги
* информации об остатках товаров
* списка актуальных предложений
* динамической информации (акции, промо-коды и т.д.)
и т.д.
## Требования к таблице
Основные требования по формату таблицы для ее корректного подключения следующие:
1. Первая строка таблицы должна быть заполнена заголовками колонок таблицы
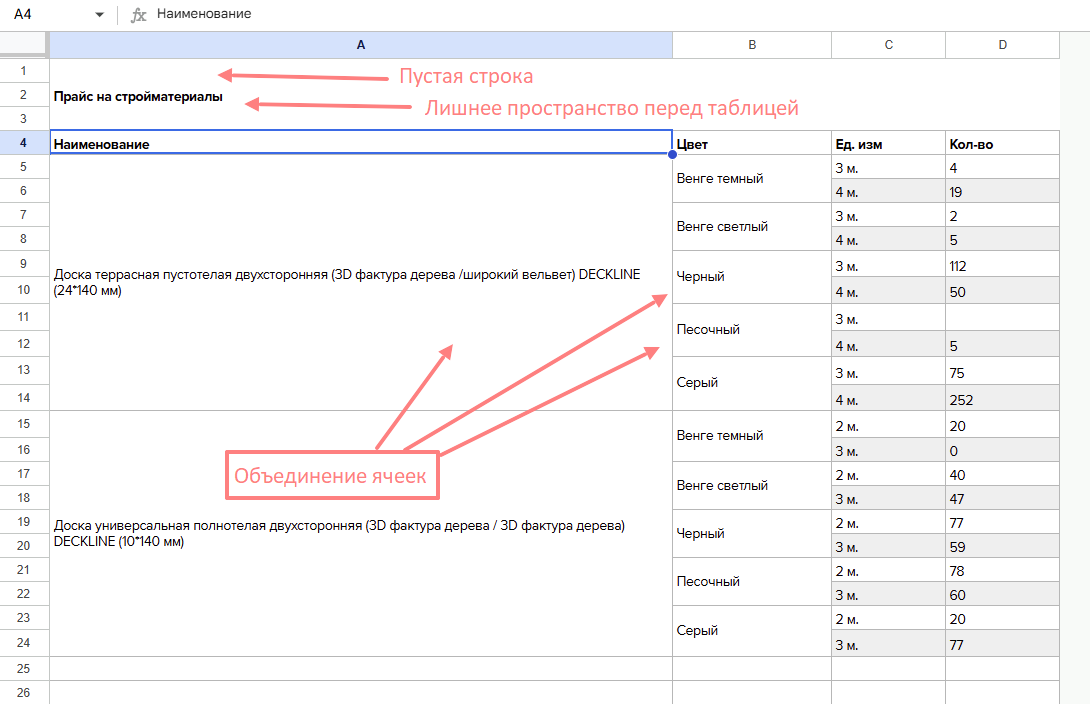
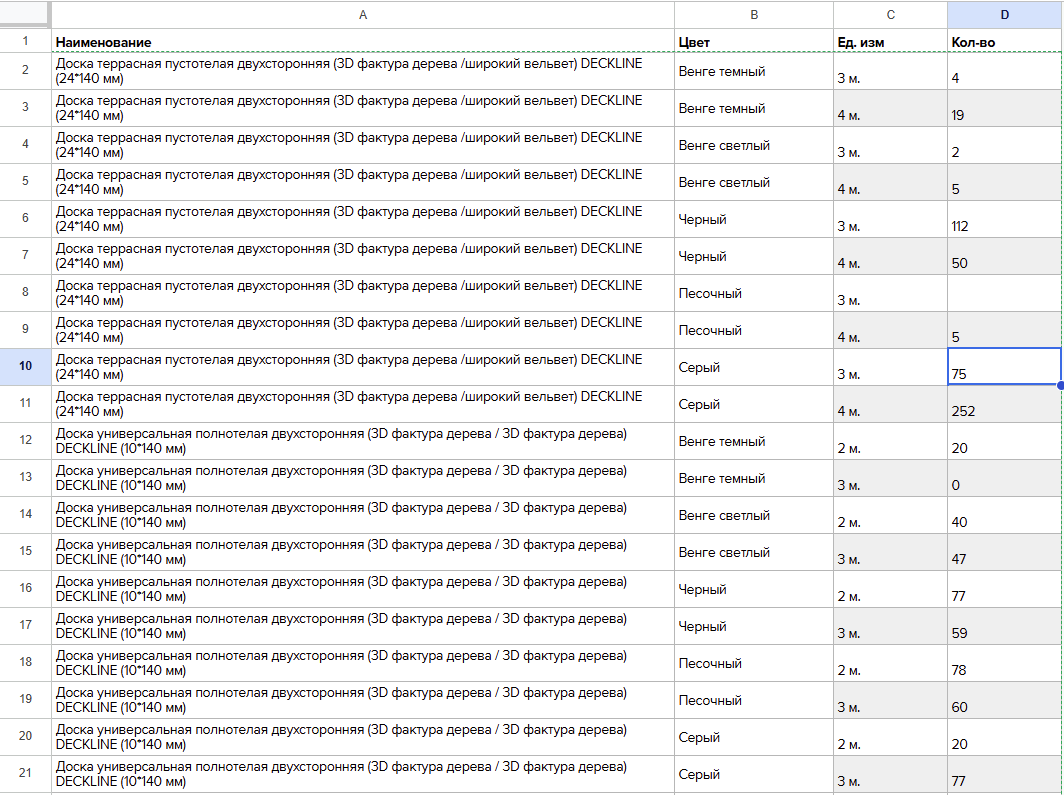
2. Таблица не должна содержать объединение строк (такие таблицы называют обычно простыми или нормализованными).
3. Дату и время необходимо вносить только в следующем формате:\
YYYY-MM-DD
\
YYYY-MM-DD HH:MM:SS
Почему важно, чтоб таблица была простой (без объединения) - чтобы корректно работали запросы к ее данным.
Приведем пример правильной и неправильной таблицы:
### Пример неправильной таблицы
### Пример правильной таблицы
## Подключение таблицы
Для подключения таблицы необходимо перейти в раздел **Таблицы** в настройках бота и выбрать один из вариантов подключения:
* загрузка таблицы из CSV-файла
* загрузка из файла Excel
* подключение Google-таблицы
При подключении таблицы из CSV-файла важно, чтобы файл был сохранен в кодировке UTF-8 с разделителями - **запятые**.
При подключении статичной таблицы (CSV / XLS) необходимо просто выбрать файл.
{% hint style="warning" %}
ВАЖНО!
1. Таблица на **Google Drive** должна быть сохранена не как таблица **.ELSX**, а как **Google-таблица**.
2. Должны быть открыты доступы к таблице, Роль - **Читатель** или **Редактор**.
{% endhint %}
При подключении к Google-таблице - нужно авторизоваться и выбрать нужную таблицу:
После выбора, откроется форма создания таблицы:
> * **Название таблиц** - Название для отображения в списке.
> * **Лист -** Возможность выбора листа Google-таблицы.
> * **Частота обновления таблицы (минуты)** - Время за которое таблица обновляется для ответов Савви. По умолчанию - 1440 минут - или раз в 24 часа. Кнопка обновления позволяет обновить данные в любой момент.
{% hint style="warning" %}
Не рекомендуем ставить обновление чаще, чем **раз в 30 минут**, т.к. каждый раз происходит скачивание таблицы, если она слишком большая, это может вызывать нагрузку на учетную запись Google, что может привести к **ограничению доступа к ней**.
{% endhint %}
В работе с таблицами есть три режима: Получение данных, Изменение и Добавление.
#### **В этом разделе руководства подробно рассмотрим Получение данных из таблицы.**
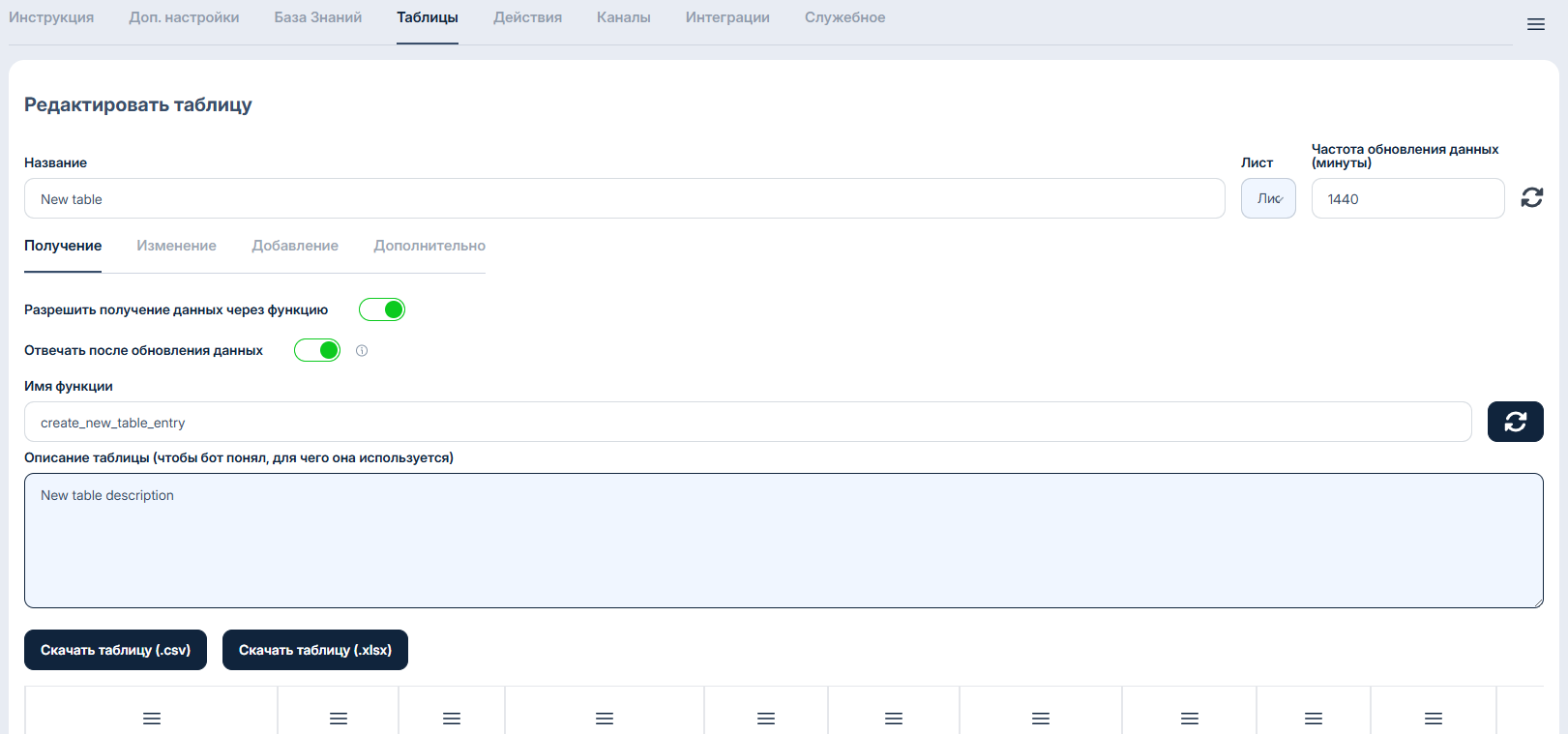
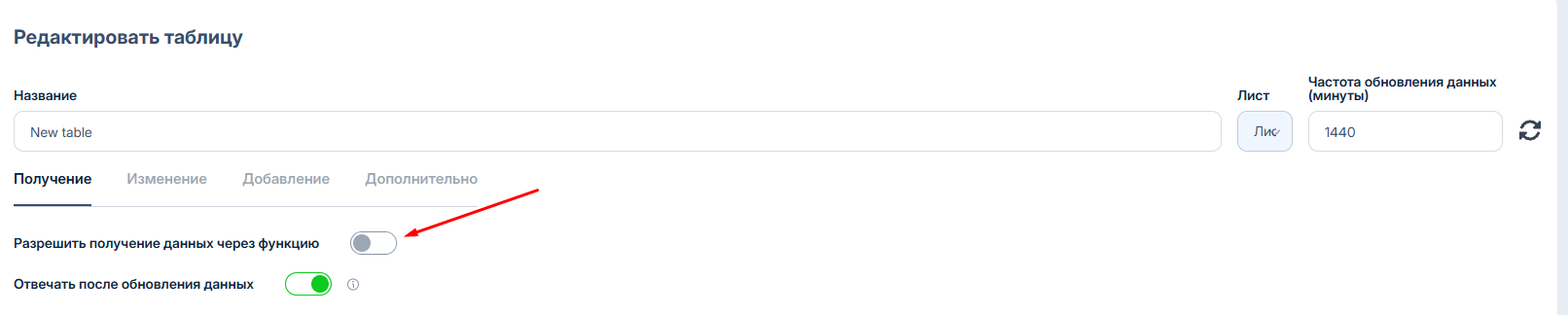
> * **Разрешить получение данных через функцию** - При включении этой настройки появятся поля **Имя функции** и **Описания таблицы**. Эта настройка дает возможность обращаться к таблице через инструкцию в промпте используя **Имя функции**.
> * **Имя функции** - Имя функции по которой Савви будет обращаться к таблице. Подробнее о функциях в разделе **"Функции".**
> * **Описание таблицы** - Основная информация описывающая значение таблицы и данных хранящихся в ней данные. По описанию Савви будет понимать, когда нужно вызывать таблицу, при каких запросах.
>
> Описание очень важная составляющая, т.к. она определяет поведение и запрос, который будет формироваться к таблице.
{% content-ref url="../../osnovnye-nastroiki/prompts/prompts-2" %}
[prompts-2](https://docs.suvvy.ai/ru/osnovnye-nastroiki/prompts/prompts-2)
{% endcontent-ref %}
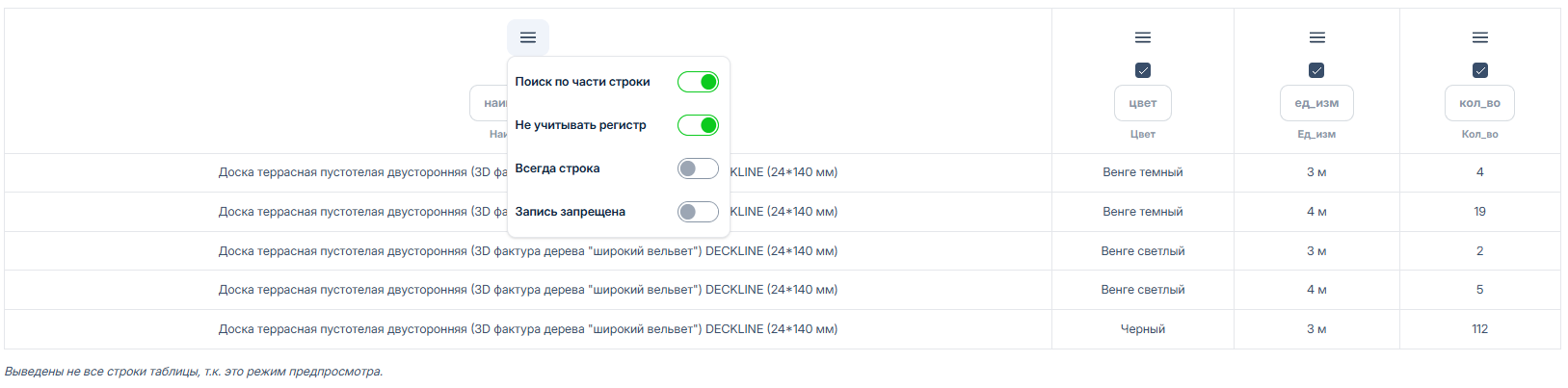
#### Параметры колонок
{% hint style="warning" %}
При заполнении колонок таблицы важно соблюдать правило - наименование должно быть **без пробелов** и должно отражать суть значений в колонке.
{% endhint %}
Таблица отображается не полностью, только первые 5 строк таблицы - просто для понимания какие данные в ней хранятся.
> * **Поиск по части строки** - позволяет находить данные в таблицы даже если было часть текста из колонки.
> * **Не учитывать регистр** - позволяет не учитывать регистр слова (заглавная или строчная) и находить названия написанные заглавными буквами даже если отбор сделан по слову со строчной буквы.
> * **Всегда строка** - позволяет работать с числами как со строкой.
> * **Запись запрещена** - позволяет защитить от записи и изменений ячейки в колонке.
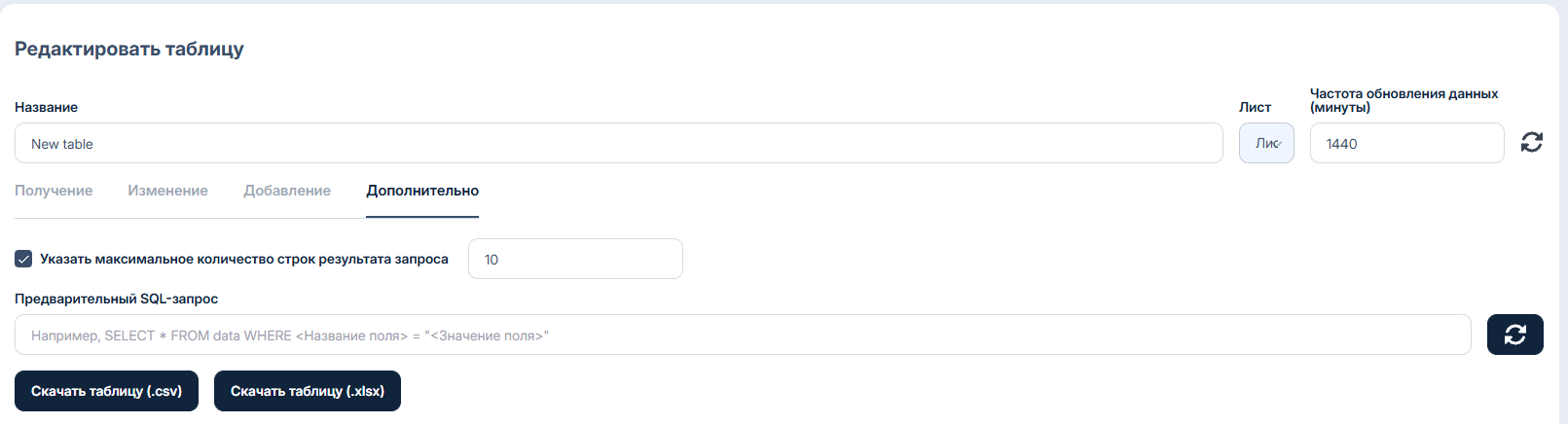
#### Раздел - Дополнительно
> * **Указать максимальное количество строк результата запроса** - мы можем ограничить объем данных получаемый из таблицы для уменьшения стоимости ответа. Эту функцию мы можем применять вместо использования оператора [LIMIT](https://docs.suvvy.ai/ru/rabota-s-tablicami/tablicy-csv-xls-google/poluchenie-dannykh#primer-otbora-s-ispolzovaniem-limit).
> * **Предварительный SQL-запрос** - Заранее подготовленный запрос к таблице, выполняется перед запросом от нейросети. Может быть использован как предварительный фильтр.
>
> **Например:**
> \
> Вы заранее знаете, что при любом запросе вам нужно получить из таблицы только строки, где колонка "Доступность" = "ДА".
>
> В таком случае, вы можете прописать это в предварительном запросе вместо того, чтобы говорить боту писать это.
## Работа с таблицей
Первое, что важно знать - Савви понимает в какой момент нужно взять данные из таблицы по описанию таблицы.
Кроме того, всегда есть возможность обращаться к таблице как к функции из основной инструкции:
> Например, для того, чтобы обратиться к таблице мы можем использовать конструкцию:
>
> "Если клиент.......вызови функцию <название фукнции таблицы>", где <название фукнции таблицы> - конкретное название функции из таблицы, которое было создано при создании таблицы.
{% tabs %}
{% tab title="Вызов таблицы из инструкции" %}
```
#ИНФОРМАЦИЯ ПО СТРОЙМАТЕРИАЛАМ
Если клиент спрашивает стоимость стройматериалов выполни следующие действия:
1. Обязательно уточни у клиента наименование материала и цвет.
2. Далее вызови функцию deckline_terrace_board_table(), и передай туда материал и цвет.
```
{% endtab %}
{% endtabs %}
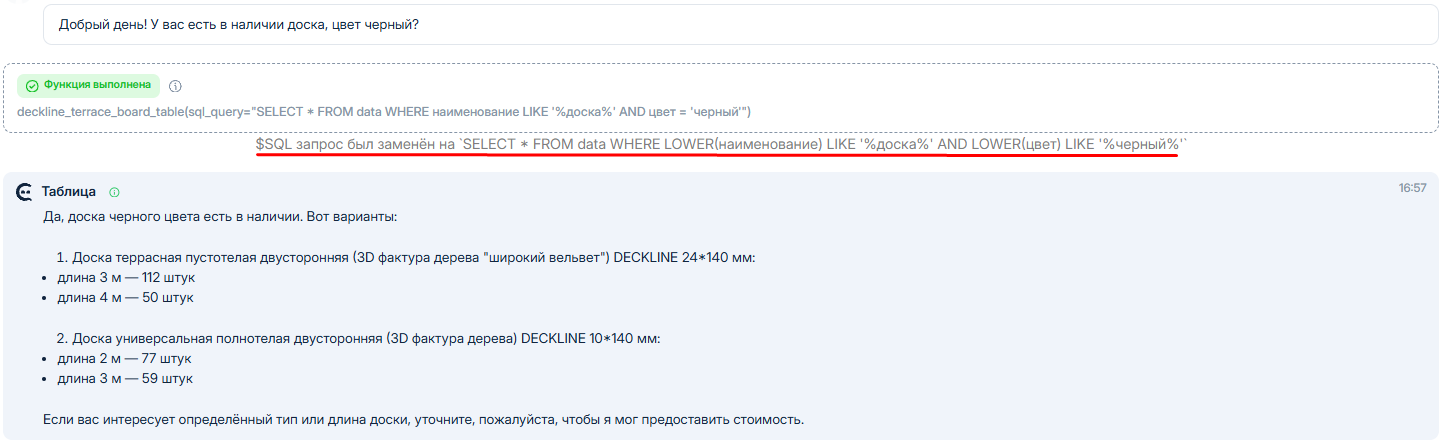
Как видно из промпта, мы сначала запросили у клиента необходимые параметры, а далее передали в функцию конкретные пункты по которым нам требуется сделать отбор.
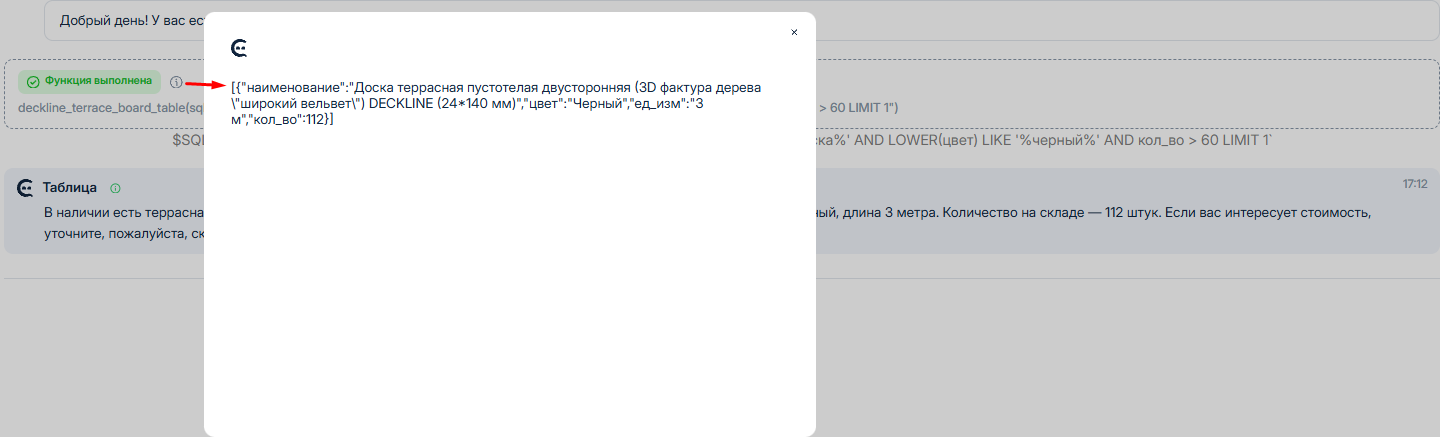
При вызове таблицы, если мы занимаемся отладкой (подробнее об отладке ниже), мы можем увидеть, что Савви создает специальный SQL-запрос к таблице для того, чтобы получить конкретные данные:
{% content-ref url="../../osnovnye-nastroiki/prompts/prompts/otladka-instrukcii" %}
[otladka-instrukcii](https://docs.suvvy.ai/ru/osnovnye-nastroiki/prompts/prompts/otladka-instrukcii)
{% endcontent-ref %}
Савви сам создает SQL-запросы при помощи специального движка (DSG), но важно в целом понимать принципы языка SQL-запросов, поэтому, если язык вам еще не знаком, рекомендуем почитать блок ниже:
SQL (Structured Query Language)
SQL (Structured Query Language) — это язык, который используется для работы с базами данных. Представь базу данных как большую таблицу в Excel, где хранятся всевозможные данные — например, информация о клиентах магазина, товарах, заказах и так далее. С помощью SQL мы можем добавлять данные в таблицы, извлекать их, изменять или удалять — и всё это быстро и эффективно.
Вот основные принципы и операторы, которые помогут понять, что такое SQL:
1. **SELECT** — это оператор, который позволяет "достать" нужные данные из таблицы. Например, если у нас есть таблица с клиентами, и мы хотим узнать все их имена, мы пишем запрос:
```sql
SELECT имя FROM клиенты;
```
Это примерно как выбрать только одну колонку в Excel.
2. **FROM** — указывает, откуда мы берем данные. В предыдущем примере мы выбрали колонку "имя" из таблицы "клиенты".
3. **WHERE** — оператор для фильтрации данных. Например, если нас интересуют только те клиенты, которые живут в Москве:
```sql
SELECT имя FROM клиенты WHERE город = 'Москва';
```
Это помогает отобрать только те строки, которые соответствуют нашим условиям.
4. **INSERT INTO** — позволяет добавить новую информацию в таблицу. Например, добавим нового клиента:
```sql
INSERT INTO клиенты (имя, город) VALUES ('Иван', 'Москва');
```
Это как добавить новую строку в таблицу.
5. **UPDATE** — используется для изменения данных. Например, если Иван переехал из Москвы в Санкт-Петербург, то мы можем обновить его данные:
```sql
UPDATE клиенты SET город = 'Санкт-Петербург' WHERE имя = 'Иван';
```
6. **DELETE** — удаляет данные из таблицы. Если Иван больше не наш клиент, мы можем удалить его:
```sql
DELETE FROM клиенты WHERE имя = 'Иван';
```
7. **Основные принципы** SQL заключаются в том, что он работает с таблицами, состоящими из строк и колонок. Строки — это отдельные записи (например, данные конкретного клиента), а колонки — это свойства записей (например, имя, возраст, город).
SQL также может объединять таблицы. Например, у нас есть таблица с заказами и таблица с клиентами, и мы можем объединить их, чтобы увидеть, какие клиенты сделали какие заказы.
Всё это позволяет эффективно управлять данными, извлекать нужную информацию и выполнять любые операции с базой данных. Важный момент — SQL достаточно прост в освоении, и даже с минимальными знаниями можно уже начинать писать полезные запросы.
### Отборы на запросы к таблице
{% hint style="warning" %}
**Важно**\
Поскольку таблицы могут содержать довольно большое количество данных и за одно обращение Савви может получать множество строк из таблицы, очень важно:
1. Предварительно накладывать максимально возможный отбор на запрос к таблице.
2. Использовать искусственное ограничение на количество выбираемых данных в разделе настройки таблиц - [Дополнительно](#razdel-dopolnitelno).
{% endhint %}
Если мы говорим про пункт 1, то накладывать отбор на запросы можно путем указания того, что мы должны передать в таблицу, в рассматриваемом выше примере это был отбор по наименованию и цвету. Цвет в данном случае позволяет сужать поиск.
#### Пример числового отбора
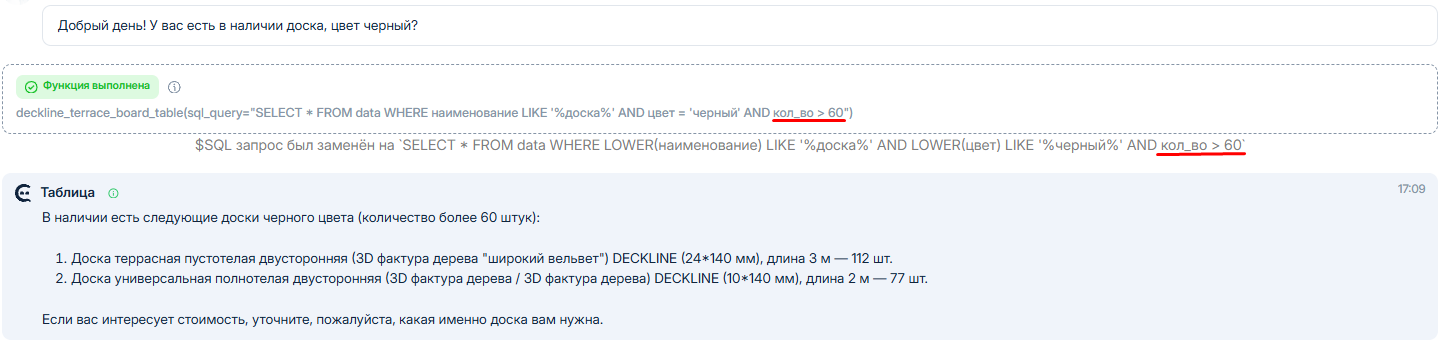
Кроме того, мы можем накладывать отборы на поля с типом Дата и число.
К примеру, если мы хотим указать, чтобы Савви предоставил материалы только там, где количество больше **60**, мы можем сделать это через промпт/инструкцию таким образом:
{% tabs %}
{% tab title="Дополнительный отбор по числовому полю" %}
```
#ИНФОРМАЦИЯ ПО СТРОЙМАТЕРИАЛАМ
Если клиент спрашивает стоимость стройматериалов выполни следующие действия:
1. Обязательно уточни у клиента наименование материала и цвет.
2. Далее вызови функцию deckline_terrace_board_table(), и передай туда материал и цвет и
только те, где количество > 60.
```
{% endtab %}
{% endtabs %}
В этом случае в SQL-запрос к таблице добавится дополнительное условие и мы получим выборку с учетом дополнительного отбора:
#### Пример отбора с использованием LIMIT
Бывает так же, что несмотря на отборы по колонкам все равно в выборка получается большой, тем самым перегружает контекст и увеличивает стоимость запроса.
В этом случае дополнительном мы можем применять искусственное ограничение по количеству выбираемых записей из таблицы используя оператор **LIMIT**.
Например формулируя промпт таким образом:
{% tabs %}
{% tab title="Отбор записей через LIMIT" %}
```
#ИНФОРМАЦИЯ ПО СТРОЙМАТЕРИАЛАМ
Если клиент спрашивает стоимость стройматериалов выполни следующие действия:
1. Обязательно уточни у клиента наименование материала и цвет.
2. Далее вызови функцию deckline_terrace_board_table(), и передай туда материал и цвет и
только те, где количество > 60, но не более 1 запись.
```
{% endtab %}
{% endtabs %}
В этом случае фраза **"не более N записей"** позволяет наложить отбор на таблицу и получить первые N подходящие записи.
Вот что вернул отбор таблицы, здесь только одна запись:
В случае, если такой промт работает не стабильно, можно дополнительно указать в текст в скобочках подсказку для модели:
{% tabs %}
{% tab title="Отбор записей через LIMIT" %}
```
#ИНФОРМАЦИЯ ПО СТРОЙМАТЕРИАЛАМ
Если клиент спрашивает стоимость стройматериалов выполни следующие действия:
1. Обязательно уточни у клиента наименование материала и цвет.
2. Далее вызови функцию deckline_terrace_board_table(), и передай туда материал и цвет и
только те, где количество > 60, но не более 3 записей (оператор LIMIT).
```
{% endtab %}
{% endtabs %}
### **Предварительный SQL-запрос**
Бывают случаи, когда в значениях колонки мы хотим работать с конкретными значениями. Они нам заранее известны.
Например, колонка имеет такие значение городов:
* Москва
* Санкт-Петербург
* Волгоград
* Зеленогорск
* Тюмень
Но мы знаем, что согласно условиям задачи нам требуется находить данные только по значениям
* Санкт-Петербург
* Волгоград
* Зеленогорск
Исходя из того, что мы обсуждали ранее, мы можем описать эти отборы в промте, например:
```
При обращении к функции <функция таблицы> находи значения только по городам "
Санкт-Петербург, Волгоград, Зеленогорск.
```
И это будет работать, НО, наша задача всегда повышать качество ответов и снижать вероятность ошибок. Как мы ранее описывали в разделе "Лучшие практики" основой повышения качества является уменьшение инструкции и там где это возможно использование алгоритмических механизмов.
{% content-ref url="../../osnovnye-nastroiki/prompts/prompts" %}
[prompts](https://docs.suvvy.ai/ru/osnovnye-nastroiki/prompts/prompts)
{% endcontent-ref %}
Поэтому здесь к нам на помощь приходит механизм предварительного отбора к таблице, который задается через поле **Предварительный SQL-запрос.** Прописав в нем предварительный запрос к таблице, мы сразу получаем готовую выборку только по этим городам без дополнительной необходимости накладывать его внутри инструкции и увеличивая тем самым контекст и нагрузку на модель:
### Работа с кросс-таблицами
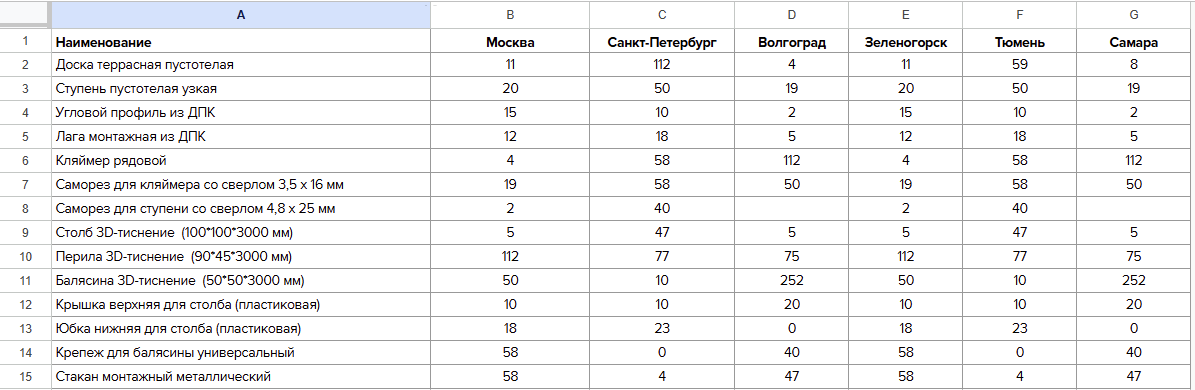
Существует такой тип таблиц, который называется **кросс-таблицами** или **матрицами данных**.
В этой таблице поиск данных происходит на пересечении значений первой колонки (обычно представляющей категории) и остальных колонок (представляющих другие измерения данных).
Кросс-таблицы очень удобны для представления информации, когда нужно визуализировать зависимость между двумя или более переменными, что часто используется в статистике и аналитике.
Для конкретного примера представьте, что у вас есть таблица с данными о продажах товаров, где первая колонка — это названия товаров, а остальные колонки — продажи в различных регионах. Тогда каждое значение внутри таблицы представляет собой количество продаж конкретного товара в конкретном регионе:
Может возникнуть вопрос, как в этом случае составлять отборы и может ли Савви сам получить данные по таким таблицам?
**Да! Может!**
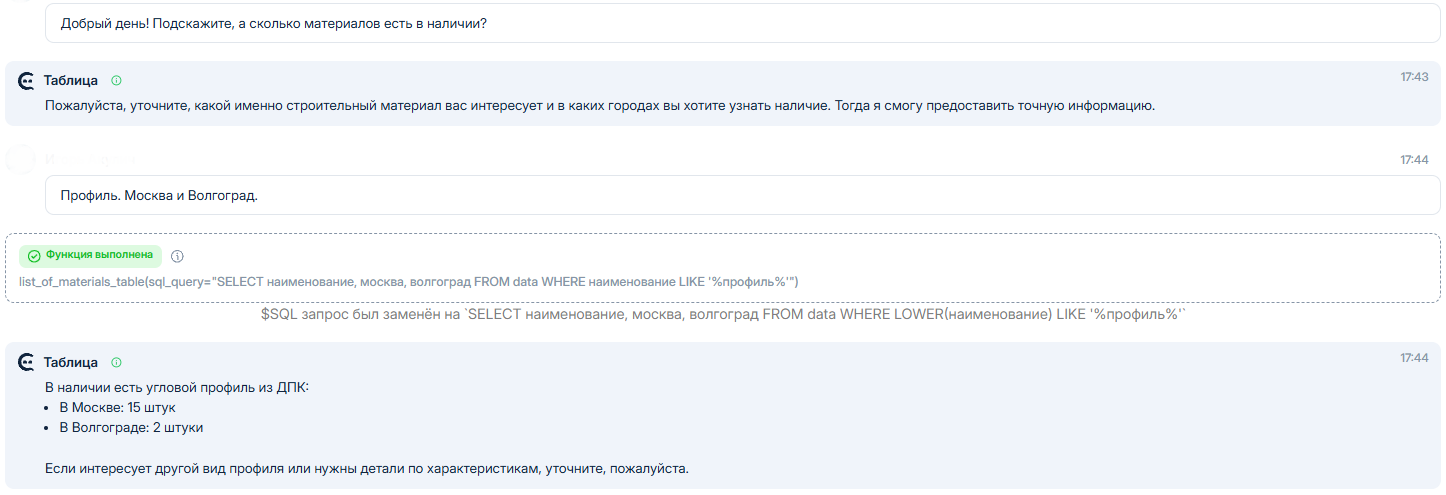
Во-первых, даже если мы ничего не будем принудительно описывать - он с справится с задачей используя простой промпт:
```
1. Уточни у клиента материал и в каких городах интересует информация.
2. Обратись к таблице материалов вызвав функцию list_of_materials_table() и
передай туда материал и список городов.
```
Результат мы получим такой:
Как видно, он понял в каких колонках что находится и вызвал верные отборы.
Однако, когда речь идет о больших инструкциях, и если мы говорим о качестве и стабильности ответов, можно использовать дополнительные приемы.
Мы можем добавить внутри описания таблицы следующий пример инструкции:
````markdown
Используй этот шаблон для поиска данных по материалам и городам:
```sql
SELECT <города> FROM data WHERE наименование = <наименование материала>
Поменяй <города> and <наименование материала> с вашими критериями поиска.
```
````
Четко заданный шаблон при больших основных инструкциях будет давать лучшую точность.
### Смысловой поиск
Платформа "Савви" позволяет реализовать поиск данных по таблице, не только с использованием типовых отборов SQL, но и через дополнительную функцию, в основе которой лежит технология векторного поиска, аналогичная поиску при работе с [большими файлами](https://docs.suvvy.ai/ru/baza-znanii/baza-znanii/bolshie-faily).
Данный способ поиска подходит в тех случаях, когда нам надо наложить отбор на таблицу не по фиксированному значению или маске, а по смыслу, то есть найти все строки у которых содержание в колонке поиска соответствует смыслу поискового запроса. Например, на базе данной технологии реализован блок работы с [Wildberries](https://docs.suvvy.ai/ru/kanaly/marketpleisy/wildberries). В подсистеме WB пользователи подгружают таблицу, с типовыми вопросами клиентов и необходимыми ответами на них, а система, при получении реального вопроса клиента, уже по смыслу находит подходящие варианты и формирует ответ.
#### Как настроить?
Рассмотрим порядок настройки поиска по смыслам, на примере бота для автосервиса. Задачей бота является предоставление информации клиентам по стоимости услуг по ремонту автомобиля. У организации существует прайс-лист на услуги, в разрезе моделей и наименований ремонтных работ:
Данную таблицу мы загружаем в бота, порядок подключения описан в [разделе выше](#podklyuchenie-tablicy). Ключевым отличием является то, что работа с данной таблицей будет строиться через подсистему "Действия", поэтому в настройках самой таблицы флаг использование - выключаем.
Сохраняем настройки таблицы и переходим на закладку **Действия**. Добавляем новое, выбираем тип шага - **Вызов таблицы**.
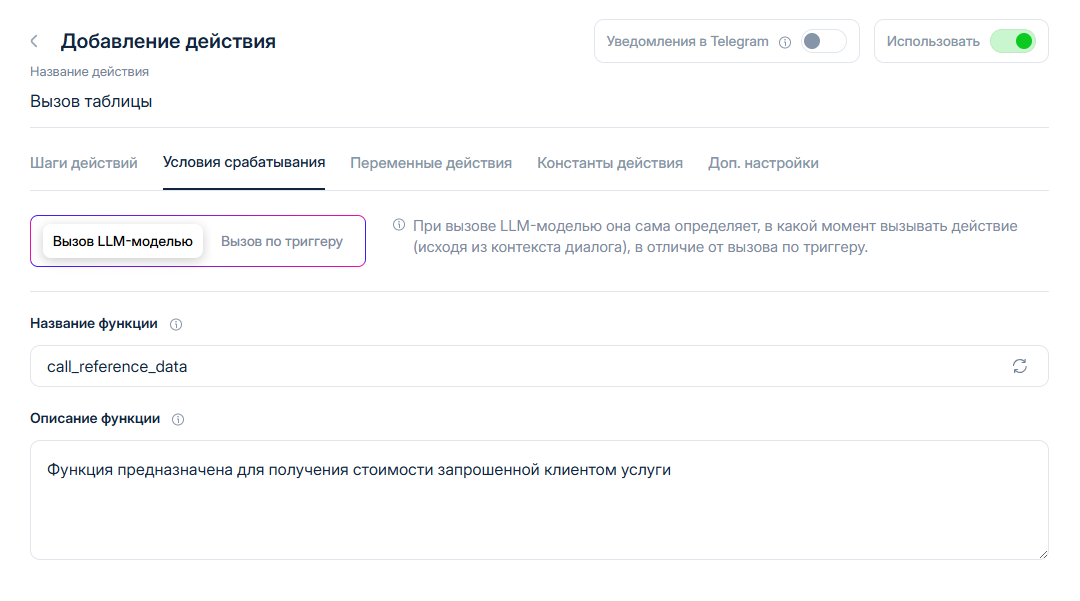
Заполняем название функции и ее описание. Описание является инструкцией для бота, в каких случаях и для чего данная функция должна применяться.
Если необходимо настроить вызов по триггеру следуем этой инструкции: [Вызов действий по триггеру.](https://docs.suvvy.ai/ru/deistviya/vyzov-deistvii-po-triggeru)
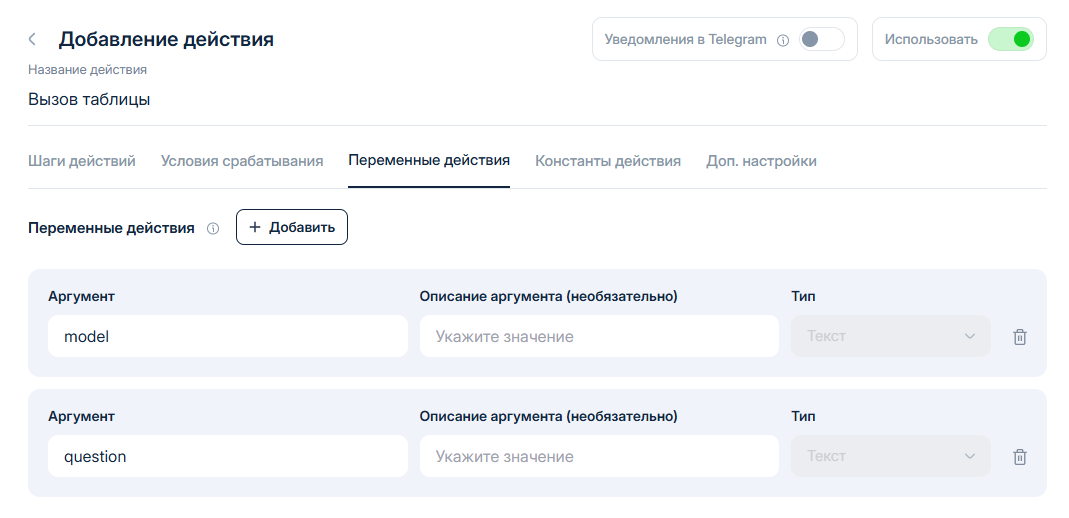
Так как функция у нас должна будет производить поиск по запросу клиента, то мы должны в действие передать этот запрос, а также передать модель которой интересуется клиент. Для этого переходим в раздел **Переменные действия** и назначаем аргументы: {model} и {question}
После того как мы заполнили аргументы, переходим в раздел - **Шаги действия.** Где необходимо выбрать таблицу к которой будут выполняться запросы и написать сами запросы. Платформа позволяет задать не один запрос, а несколько. Они будут выполняться последовательно. В нашем примере было использовано два запроса. Первый запрос находил все строки по указанной клиентом модели, а второй запрос искал уже услугу.
Также, при необходимости, можно использовать следующие настройки:
> **Возвращать в функцию ошибку, если ничего не было найдено** - если при запросе к таблице релевантного ответа не было найдено в диалоге будет сообщение об ошибке, но диалог при этом не остановится.
>
> 
>
> **Соблюдать настройки колонок** - при включенной настройке будут учитываться установленные параметры колонок в разделе Таблицы.
>
> 
>
> **Поместить результата поиска в переменную** - установить переменную, в которую будет записываться результат поиска из выбранной колонки
>
> 
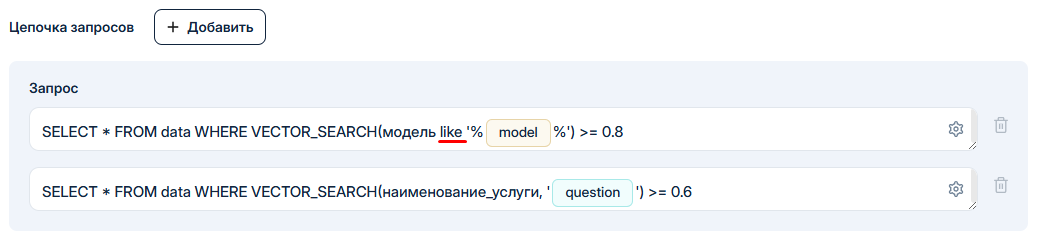
Примеры запросов указанные на картинке выше являются запросами со смысловым поиском. За смысловой поиск по таблице в платформе отвечает функция VECTOR\_SEARCH. Она имеет следующий формат:
VECTOR\_SEARCH(ИмяКолонки, ПоисковыйЗапрос) >= ТочностьПоиска
* Имя колонки - колонка по которой будет осуществляться смысловой поиск. Имя колонки задается при подключении таблицы, в разделе "Таблицы";
* Поисковый запрос - это запрос, полученный от клиента, то есть то, что мы будем искать в таблице. Поисковой запрос передается ботом в аргумент функции. В нашем случае это аргумент "model" или "question";
* Точность поиска - это число, от 0 до 1, которое задает точность поиска. Чем выше значение тем более строгим будет поиск, то есть при 1 должно быть практически полное совпадение запроса клиента и значения в поисковой колонке. Мы рекомендуем использовать значения от 0.5 до 0.8, в зависимости от условий. На примере выше поиск по модели требуется максимально строгий, поэтому стоит значение 0.8, а поиск по услугам должен возвращать все близкие по смыслу варианты - поэтому точность стоит уже ниже - 0.6.
Ниже приведем пример запроса, его можно использовать один в один, заменяя только имя колонки и имя аргумента функции (если у Вас оно указано другое):
```
SELECT * FROM data WHERE VECTOR_SEARCH(наименование_услуги, 'question') >= 0.6
```
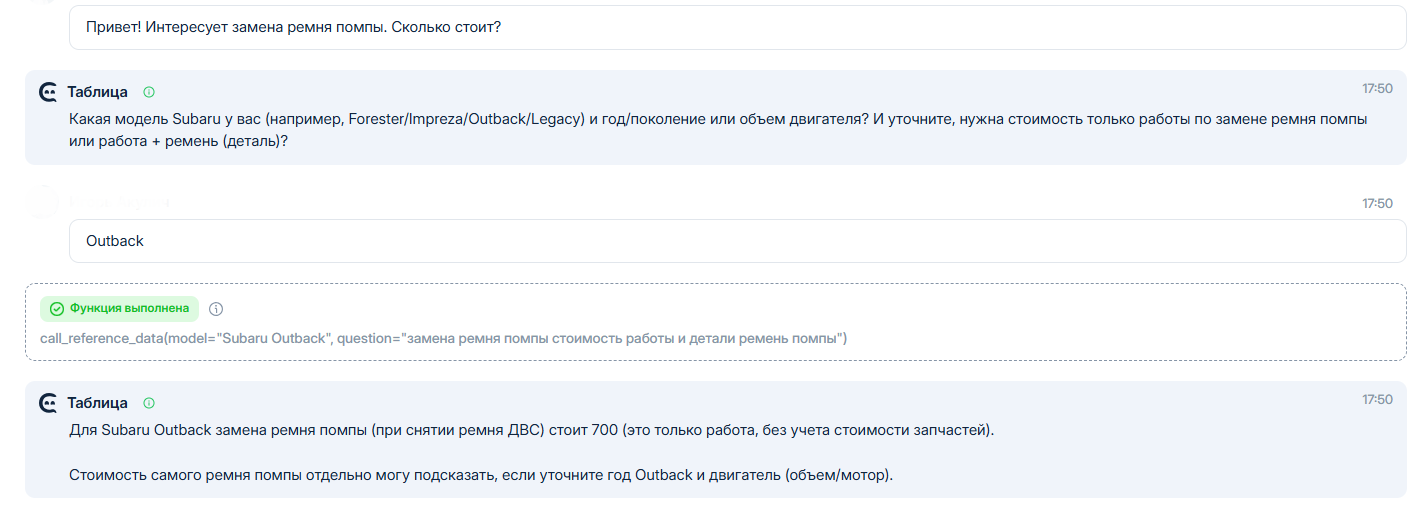
Пример диалога с использованием смыслового поиска:
При запросе были получены следующие результаты и выбран для ответа наиболее подходящий:
#### Оптимизация цепочек запросов
Как мы упомянули выше, платформа позволяет задать не один запрос, а сразу несколько, как и сделано в описанном выше примере. Также мы видим, что в цепочке запросов, оба запроса использовали функцию векторного поиска - поиска по смыслам. Необходим отметить, что данный поиск не является быстрым и если возможно его заменить типовым поиском SQL, это надо всегда делать. В нашем примере, если мы боту дадим инструкцию узнавать у клиента точное название модели и передавать его в запрос, мы можем выполнить поиск по моделям используя оператор like (поиск по маске), и не использовать функцию векторного поиска. Это будет работать гораздо быстрее и лучше: